In questo articolo creeremo la libreria dati che permetterà allo strato dei servizi di parlare con il Database, questa libreria sarà quella in cui porremo per prima cosa la classe per lavorare con SQL Server, poi vedremo come poter utilizzare anche gli altri due database. Come già indicato nei precedenti articoli, volendo introdurre in modo semplice la creazione di classi per effettuare il CRUD, non useremo alcun framework dati, solo la libreria dati standard ADO.Net, che poi è quello che utilizzano i framework dati creando automaticamente le loro classi per voi. Prendetelo come un esercizio per imparare cosa c’è dietro ai framework e come funziona in modo tale da permettervi di poter giocare con i dati evitando di complicarvi la vita quando non serve.
Il progetto dati per Sql Server
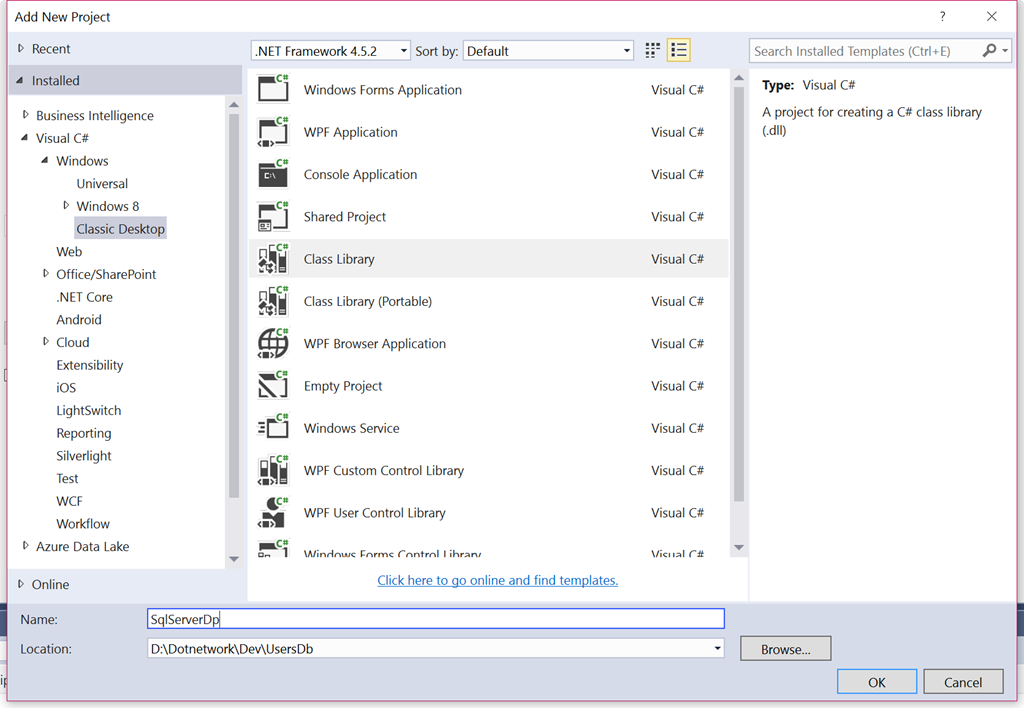
Iniziamo questa terza puntata dedicata alla nostra applicazione multi tier realizzando lo strato dati di uno dei tre database che intendiamo mettere a disposizione dei nostri utenti, pertanto, per prima cosa creiamo un nuovo progetto libreria di classi:
![07_userdb_01_AddProject[5]](http://www.sabrinacosolo.com/wp-content/uploads/07_userdb_01_AddProject5.png "07_userdb_01_AddProject[5]")
Ci posizioniamo sulla Solution e quindi utilizziamo il menu contestuale per aprire il menu Add > New Project…
![07_userdb_02_AddProject[5]](http://www.sabrinacosolo.com/wp-content/uploads/07_userdb_02_AddProject5.png "07_userdb_02_AddProject[5]")
Creiamo un progetto di tipo Class Library e lo chiamiamo SqlServerDp.
Una volta generato il nuovo progetto, procediamo alle modifiche preliminari:
![07_userdb_03_DeleteClass1[4]](http://www.sabrinacosolo.com/wp-content/uploads/07_userdb_03_DeleteClass14.png "07_userdb_03_DeleteClass1[4]")
Cancelliamo la Class1.cs.
![07_userdb_04_UpdateProperties[5]](http://www.sabrinacosolo.com/wp-content/uploads/07_userdb_04_UpdateProperties5.png "07_userdb_04_UpdateProperties[5]")
Modifichiamo quindi le proprietà della nuova .dll, anche in questo caso pongo il prefisso Dnw. davanti al nome della libreria perché è una mia preferenza per poter riconoscere a colpo d’occhio tutte le mie .dll rispetto a quelle di terze parti o di sistema nella cartella di installazione. Ho anche modificato l’Assembly Information in modo da inserire i dati di identificazione della libreria. Ed ho aggiunto un icona personalizzata. Oltre a questo, ho firmato la libreria con la chiave dotnetwork come abbiamo fatto per l’eseguibile e l’altra libreria.
La creazione della classe Data Provider
Andiamo ora a creare la nostra classe Data Provider, UsersDp, che ci permetterà di fare tutte le operazioni di CRUD (Create Read Update Delete) che riguarderanno la tabella TbUsers sul database SQL Server.
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Data;
using System.Data.Sql;
namespace Dnw.Data.SqlServer
{
class UsersDp
{
private string mConnnectionString;
public UsersDp(string connectionString)
{
mConnnectionString = connectionString;
}
}
}La struttura base della classe è questa, l’unica cosa importante è che la classe richiederà di ricevere una stringa di connessione per poter essere istanziata, lo inseriamo come vincolo perché senza stringa di connessione non possiamo parlare con il database è quindi opportuno che sia un dato obbligatorio.
Aggiungiamo ora per prima cosa i 4 comandi SQL che serviranno per modificare o per leggere il contenuto della tabella.
private const string SQL_Insert = @"
INSERT INTO [dbo].[TbUsers]
([WinUser]
,[WinDomain]
,[UserName]
,[Computer]
,[LoginType]
,[Password])
VALUES
(@WinUser
,@WinDomain
,@UserName
,@Computer
,@LoginType
,@Password )
SELECT @@IDENTITY AS 'Identity'; ";
private const string SQL_Update = @"
UPDATE [dbo].[TbUsers]
SET [WinUser] = @WinUser
,[WinDomain] = @WinDomain
,[UserName] = @UserName
,[Computer] = @Computer
,[LoginType] = @LoginType
,[Password] = @Password
WHERE ID = @ID
";
private const string SQL_Delete = @"
DELETE FROM [dbo].[TbUsers]
WHERE ID = @ID
";
private const string SQL_Select = @"
SELECT [ID]
,[WinUser]
,[WinDomain]
,[UserName]
,[Computer]
,[LoginType]
,[Password]
FROM [dbo].[TbUsers]
";Li definiamo in altrettante costanti, una volta creato il nostro Data Provider verificheremo che funzionino correttamente tutti e quattro. Prima di procedere a creare i metodi che modificheranno o leggeranno il database, dobbiamo referenziare la nostra libreria Jolly, UsersEntities, in modo tale da poter utilizzare la classe User che abbiamo creato al suo interno anche in questa libreria.
![07_userdb_07_ReferenceUserEntity[5]](http://www.sabrinacosolo.com/wp-content/uploads/07_userdb_07_ReferenceUserEntity5.png "07_userdb_07_ReferenceUserEntity[5]")
Usiamo il comando Add Reference dal nodo References del Progetto SqlServerDp e selezioniamo Projects, Solution, e selezioniamo UsersEntities.
![07_userdb_08_ReferenceUserEntity[4]](http://www.sabrinacosolo.com/wp-content/uploads/07_userdb_08_ReferenceUserEntity4.png "07_userdb_08_ReferenceUserEntity[4]")
UsersEntities sarà ora inserito fra le references di progetto, quindi potremo utilizzare la classe User che abbiamo creato al suo interno come “mezzo di trasporto” se così possiamo definirlo, dei dati dal database alla User Interface e viceversa.
Prima di procedere ulteriormente, dobbiamo creare una semplice classe di appoggio, semplice ma molto importante.
Quando si progetta una libreria di servizi, soprattutto una libreria come questa che si connette ad una risorsa esterna, quale può essere un database, ma potrebbe essere un sito web, una porta seriale o una porta USB o semplicemente una share su una rete locale, è molto probabile che possano verificarsi degli errori non controllabili da noi, quali ad esempio che il database non risponde, il sito web non è disponibile, la macchina nella rete locale è spenta eccetera.
Pertanto la nostra classe Data Provider deve gestire le eventuali eccezioni ed informare lo strato superiore ad essa che si è verificato un errore in modo Soft, per così dire, senza sollevare un eccezione diretta che potrebbe non essere intercettata e far “esplodere” il programma con un errore incomprensibile all’utente.
.Net ci permette di gestire qualsiasi errore utilizzando gli statement di tipo try catch, ma sta a noi poi gestirli in modo da informare gli utenti se si è verificato un problema non dipendente dall’applicazione in modo tale che possano intervenire.
La classe che costruiremo è una classe che permetterà alla nostra classe dati di restituire un oggetto che conterrà i dati se ve ne sono oppure un eventuale messaggio di errore.
La classe Result
Lo sviluppo di questa classe, per chi è ancora un principiante è interessante perché creeremo una classe di tipo Generic, ovvero una classe in cui possiamo definire il tipo di dati che ospiterà. Sono certa che negli articoli fino a qui inseriti, anche quelli per i beginner avrete certamente visto property che usavano classi simili a List<Myclass> oppure ObservableCollection<MyElement>. Anche Result sarà una classe che ci permetterà di definire il tipo di dato che ospiterà, vediamo come.
public class Result<T>
{
public T Data
{
get; set;
}
public string Error
{
get; private set;
}
public bool HasError
{
get
{
return (this.Error != null);
}
}
public void ClearError()
{
this.Error = null;
}
public void SetError(string description)
{
this.Error = description;
}
public void SetError(Exception ex)
{
StringBuilder sb = new StringBuilder();
sb.AppendLine(ex.Message);
sb.AppendLine(ex.StackTrace);
this.Error = sb.ToString();
}
}Come potete vedere, una classe generic viene definita dandole il nome e indicando fra Minore/Maggiore che conterrà un tipo non direttamente definito. Il fatto che sia chiamato T nel codice è semplicemente una convenzione, potrei chiamarlo X o Z e non cambierebbe nulla, si tratta di un Placeholder che sarà sostituito quando la classe verrà istanziata.
La nostra classe generica quindi conterrà, oltre al nostro dato generico, due property per gestire gli errori nel modo più semplice possibile e tre metodi ugualmente utilizzati per gestire l’errore, il fatto che l’errore sia modificabile tramite un metodo è semplicemente un assicurazione relativa all’incapsulamento, che impedisce che la property Error possa essere manipolata in modo diretto. Il fatto che abbiamo 2 metodi SetError con due diversi parametri che ci permetteranno di gestire errori da noi generati oppure errori derivati da eccezioni è una dimostrazione di quello che si chiama Polimorfismo, e dimostra che i Polimorfi non sono dei mostri con tanti tentacoli :oP.
Scherzi a parte, il polimorfismo è una delle cose più utili della programmazione ad oggetti pertanto andate a fare un giro su qualche sito serio se volete una spiegazione accurata Ad esempio qui su MSDN.
Prima di tornare alla nostra classe dati dobbiamo aggiungere ancora una parte alla nostra classe Result:
public static class Result
{
public static Result<T> Get<T>() where T : new()
{
Result<T> output = new Result<T>();
output.Data = new T();
return output;
}
}Perché ho fatto un’altra classe Result? e perché ha un modificatore static accanto a public? Si tratta di una classe Helper, che ci permette di poter generare un istanza di Result per qualsiasi oggetto, sapendo che in questa classe l’oggetto Data sarà istanziato ed utilizzabile.
Infatti, l’unico metodo di questa classe, Get che cosa fa? Crea un oggetto Result del tipo indicato e una volta che lo ha fatto crea un oggetto del tipo di dato richiesto e lo inserisce nella property Data del Result.
A cosa serve tutto questo?
public Result<List<User>> Insert(List<User> usersToInsert)
{
Result<List<User>> ret = new Result<List<User>>();
User myUser = new User();
ret.Data.Add(myUser);
return (ret);
}Nell’esempio qui sopra, abbiamo un metodo che restituisce un Result contenente una Lista di User. Se eseguissimo questo codice però, la riga che aggiunge l’oggetto alla collezione solleverebbe un eccezione che ci indicherebbe che l’oggetto Data è null quindi non possiamo aggiungervi elementi.
public Result<List<User>> Insert(List<User> usersToInsert)
{
Result<List<User>> ret = Result.Get<List<User>>();
User myUser = new User();
ret.Data.Add(myUser);
return (ret);
}Utilizzando la nostra classe helper e il suo metodo Get invece siamo certi che l’oggetto Data è stato correttamente inizializzato e l’aggiunta di un elemento andrà quindi a buon fine.
public Result<List<User>> Insert(List<User> usersToInsert)
{
Result<List<User>> ret = new Result<List<User>>();
ret.Data = new List<User>();
User myUser = new User();
ret.Data.Add(myUser);
return (ret);
}Anche il codice qui sopra funziona perfettamente, ma dovremo scrivere una riga di codice in più ogni volta ed essendo programmatori il nostro scopo primario è ridurre il codice da scrivere.
Il valore DBNull e come gestirlo
In tutti i database relazionali, quando un campo in una tabella non è mai stato inizializzato con un dato ha al suo interno il valore DBNull (NULL in sql) questo a meno che non gli sia stato assegnato al momento della creazione della tabella un valore di Default oppure che sia stato indicato con la clausola NOT NULL che impedisce che possa essere inizializzato con questo valore.
Il valore DBNull dei database ed il valore null degli oggetti .Net, sfortunatamente non coincidono, il motivo per cui sia stato fatto non ho trovato ancora qualcuno che me lo spiegasse, ma presumo si tratti di un motivo molto valido, perché questo piccolo problema crea molta confusione in chi è alle prime armi (e parlo per esperienza, agli inizi ho lanciato anatemi su chi lo aveva inventato innumerevoli volte).
.Net mette a disposizione un oggetto, System.DbNull, la cui property Value contiene l’esatto valore che tutti i Database SQL restituiscono quando un campo è NULL.
Quando leggeremo i dati della nostra tabella TbUsers dal Database, se vi fossero dei dati non inizializzati (uno a caso, la password) è necessario gestirli correttamente, altrimenti riceveremo delle eccezioni non gestite e di conseguenza saremo noi a ricevere degli anatemi dai nostri utenti.
Per gestire la conversione di un valore DBNull nel valore di default di una variabile a livello di classe creeremo un metodo Extension, non solo, visto che ci siamo lanciati nei Generics, questo sarà un metodo Generic. Allo stesso modo, quando memorizzeremo i dati sul database, sarà per noi opportuno convertire i dati nulli in DBNull perché sfortunatamente per noi, la libreria ADO.Net è abbastanza intelligente da non passare a SQL Server i parametri con valore null, considerandoli come non indicati, pertanto potremmo ricevere delle eccezioni per parametri mancanti quando invece i parametri sono presenti, solo hanno valore corrispondente al DBNull, in questo caso, convertire il null specificamente in DBNull è necessario per evitare mal di testa.
Vi ho confuso a sufficienza? Sono sicura di si, quindi vediamo subito il codice così da confondervi definitivamente o, come spero invece, chiarirvi quanto è facile fare le cose in .Net.
Cos’è un metodo extension?
Un metodo extension è un metodo statico (quindi con modificatore static) che noi possiamo scrivere e aggiungere al nostro codice per modificare una classe esistente del framework.
public static bool XxIsNullOrTrimEmpty(this String pStringValue)
{
return (pStringValue == null || pStringValue.Trim().Length == 0);
}Ve ne mostro un esempio semplice, il metodo qui sopra estende la classe string del framework aggiungendogli un metodo che è in grado di verificare ritornando true oppure false, se una stringa è nulla, vuota o contiene solo spazi. So che ne esiste uno simile nella classe string, questo metodo è stato scritto prima ancora che esistessero le extension ;o) quando usavamo ancora il framework 2.0 e poi è stato convertito in extension per evitare di riscrivere codice in giro per il mondo.
Come funziona un metodo extension: Innanzi tutto è pubblico, ed è statico, può contenere uno o più parametri, ma il primo parametro è sempre del tipo su cui il metodo deve effettuare il controllo di estensione e per indicare al compilatore che si tratta di un extension di questo tipo la dichiarazione del parametro è preceduta dalla parola chiave this.
In questo caso, il codice qui sopra tradotto in lingua umana dice:
- Prendi questa stringa
- Verifica se è nulla oppure vuota
- Ritorna vero o falso
Quando useremo questo metodo nel codice, in realtà non gli passeremo alcun parametro ecco 2 esempi:
string pippo = " ";
return pippo.XxIsNullOrTrimEmpty(); string pippo = "nonvuoto ";
return pippo.XxIsNullOrTrimEmpty(); Il primo esempio tornerà true, il secondo esempio tornerà false, il parametro non viene passato al metodo extension, perché il primo parametro, marcato con this indica che il metodo deve essere eseguito sull’oggetto chiamante.
Perché ho detto che creeremo un metodo extension generico?
Perché per evitare di dover scrivere lo stesso metodo per tutti i tipi di dato .net che possono essere memorizzati in un database, scriveremo un metodo extension di Object, la classe base C# da cui derivano tutti gli oggetti e poi utilizzeremo i generics per permetterci di applicare l’extension a qualsiasi tipo di dato ci interessi.
Per prima cosa, spostiamoci sul progetto SqlServerDp, e con il tasto destro sul menu contestuale scegliamo Add > New Item… e scegliamo un oggetto Class, chiamiamolo DbNullExtensions.cs.
using System;
namespace Dnw.Data.SqlServer
{
public static class DbNullExtensions
{
...
}
}La nostra classe inizialmente sarà questa, dopo che avremo aggiunto il modificatore static perché vi metteremo all’interno solo metodi statici.
public static T XxCheckDbNull<T>(this object value)
{
return (value == DBNull.Value || value == null) ? default(T) : (T)value; // <---- OPTIMIZED TO AVOID NESTED CALLS
}
public static T XxCheckDbNull<T>(this object value, T defaultValue)
{
return (value == DBNull.Value || value == null) ? defaultValue : (T)value;
}qui sopra potete vedere il nostro primo metodo extension, lo abbiamo scritto ancora una volta utilizzando il polimorfismo, ovvero lo abbiamo definito in 2 forme diverse, la forma più articolata, che accetterà un valore di default arbitrario (da usare ad esempio se volessimo inizializzare una data NULL con un valore come ad esempio 01/01/2000) la seconda forma, semplicemente imposterà il valore del dato al valore di default dell’oggetto passato. Ogni oggetto del framework ha un valore di default, che è importante soprattutto per gli oggetti non nullabili come le date, gli interi e i numeri in generale.
Come è possibile notare dal codice riportato qui sopra, abbiamo fatto un metodo che estende l’object o meglio la classe Object del framework, infatti il primo parametro passato ad entrambi i metodi è di tipo object e contiene il modificatore this.
Al contempo, i nostri metodi sono generici, ovvero possiamo specificare un tipo T arbitrario che definiremo al momento dell’uso e quando un oggetto viene passato al metodo, viene controllato il suo valore, verificato se tale valore fosse DbNull.Value, e in caso affermativo verrebbe restituito il valore di default del tipo di dato specificato in un caso oppure il valore di default indicato come secondo parametro nella seconda versione del metodo.
public static object XxTryParseToDBNull<T>(this object valueToBeConverted)
{
return XxTryParseToDBNull<T>(valueToBeConverted, default(T));
}
public static object XxTryParseToDBNull<T>(this object valueToBeConverted, T forcedDbNullValue)
{
if (valueToBeConverted == null)
{
return (DBNull.Value);
}
if (valueToBeConverted == DBNull.Value)
{
return (valueToBeConverted);
}
if (valueToBeConverted.GetType() == typeof(T))
{
T tempValue;
try
{
tempValue = (T)valueToBeConverted;
}
catch (Exception)
{
tempValue = default(T);
}
if (tempValue.Equals(default(T)) || tempValue.Equals(forcedDbNullValue))
{
return (DBNull.Value);
}
else
{
return (valueToBeConverted);
}
}
else
{
return (valueToBeConverted);
}
}Il secondo metodo, anche in questo caso con 2 diverse versioni è quello che ci serve per riconvertire un oggetto in DbNull se contiene il valore di default di un dato oppure se contiene un valore arbitrario da noi stabilito.
Anche in questo caso è stato creato come extension della classe object del framework ed utilizza il tipo generico per effettuare la conversione che, come si può notare dal secondo metodo (che è chiamato dal primo) viene effettuata gestendo eventuali eccezioni per fornire sempre e comunque un valore da memorizzare quando non fosse possibile la conversione.
I metodi per la gestione della tabella TbUsers sul database
Arriviamo finalmente alla classe data provider della nostra tabella, e ai metodi che verranno utilizzati per modificare o leggere il database.
public Result<List<User>> Insert(List<User> usersToInsert)
{
Result<List<User>> ret = Result.Get<List<User>>();
try
{
using (SqlConnection cn = new SqlConnection(mConnnectionString))
{
SqlCommand cmd = new SqlCommand();
cmd.CommandText = SQL_Insert;
cmd.CommandType = CommandType.Text;
cmd.Connection = cn;
cn.Open();
foreach (User usr in usersToInsert)
{
SqlParameter[] para = new SqlParameter[] {
new SqlParameter("@WinUser", usr.WinUser.XxTryParseToDBNull<string>())
,new SqlParameter("@WinDomain", usr.WinDomain.XxTryParseToDBNull<string>())
,new SqlParameter("@UserName", usr.UserName.XxTryParseToDBNull<string>())
,new SqlParameter("@Computer", usr.Computer.XxTryParseToDBNull<string>())
,new SqlParameter("@LoginType", usr.LoginType.XxTryParseToDBNull<TypeOfLogin>(TypeOfLogin.None))
,new SqlParameter("@Password", usr.Password.XxTryParseToDBNull<string>())
};
cmd.Parameters.Clear();
cmd.Parameters.AddRange(para);
object obj = cmd.ExecuteScalar();
if (obj != null)
{
int id = -1;
int.TryParse(obj.ToString(), out id);
usr.ID = id;
ret.Data.Add(usr);
}
}
cn.Close();
}
}
catch (Exception ex)
{
ret.SetError(ex);
}
return (ret);
}Il metodo Insert, inserirà uno o più record nel database, lo abbiamo generato in modo semplice e generico, così che possa funzionare in qualsiasi occasione. Usualmente, quando si sviluppa una user interface, si fa in modo che l’utente modifichi uno o più record usando la User Interface e dei dati mantenuti in memoria e poi usi un comando Salva per aggiornare il database, lavorando in modo disconnesso. Se si tratta di una applicazione dove non ci sono problemi di concorrenza è il modo più semplice di procedere. Se invece vi trovaste nel caso in cui è necessario gestire la concorrenza di più utenti sugli stessi dati, sarebbe necessario gestire diversamente il codice SQL. Ma al momento ci limiteremo alle basi. Se poi qualcuno volesse approfondire la concorrenza, chiedete e proveremo a studiarne un esempio.
Come presumo abbiate notato, il codice del nostro metodo è semplice, creiamo una SqlConnection, creiamo un SqlCommand con la corretta stringa SQL, creiamo i SqlParameter per i dati che inseriremo apriamo la SqlConnection ed eseguiamo una query di tipo scalar, se vi chiedete perché non c’è l’ID nei parametri è perché il campo è un campo Identity sul database, quindi non si può inserire, ma si incrementa automaticamente. Ecco perché, utilizziamo l’ExecuteScalar e non l’ExecuteNonQuery, perché l’ID appena inserito ci viene restituito dal nostro SqlCommand di inserimento e viene aggiornato sulla classe dati passata che poi sarà restituita al chiamante.
Abbiamo utilizzato sia la classe Result, sia il convertitore da valore di default a DbNull che abbiamo scritto poc’anzi.
public Result<List<User>> Update(List<User> usersToUpdate)
{
Result<List<User>> ret = Result.Get<List<User>>();
try
{
using (SqlConnection cn = new SqlConnection(mConnnectionString))
{
SqlCommand cmd = new SqlCommand();
cmd.CommandText = SQL_Update;
cmd.CommandType = CommandType.Text;
cmd.Connection = cn;
cn.Open();
foreach (User usr in usersToUpdate)
{
SqlParameter[] para = new SqlParameter[] {
new SqlParameter("@ID", usr.ID.XxTryParseToDBNull<int>())
,new SqlParameter("@WinUser", usr.WinUser.XxTryParseToDBNull<string>())
,new SqlParameter("@WinDomain", usr.WinDomain.XxTryParseToDBNull<string>())
,new SqlParameter("@UserName", usr.UserName.XxTryParseToDBNull<string>())
,new SqlParameter("@Computer", usr.Computer.XxTryParseToDBNull<string>())
,new SqlParameter("@LoginType", usr.LoginType.XxTryParseToDBNull<TypeOfLogin>(TypeOfLogin.None))
,new SqlParameter("@Password", usr.Password.XxTryParseToDBNull<string>())
};
cmd.Parameters.Clear();
cmd.Parameters.AddRange(para);
cmd.ExecuteNonQuery();
ret.Data.Add(usr);
}
cn.Close();
}
}
catch (Exception ex)
{
ret.SetError(ex);
}
return (ret);
}Il secondo metodo, Update, molto simile al primo, è il metodo che permette di aggiornare un record, andrà ad aggiornare tutti i campi di un record con un determinato ID. Utilizziamo sempre la SqlConnection, il SqlCommand i SqlParameter e questa volta, non avendo alcun dato di ritorno, usiamo l’ExecuteNonQuery per applicare la modifica al database.
Se vi state chiedendo qual’è il motivo per cui riscriviamo tutti i valori anche se l’utente potrebbe aver modificato solo uno di essi nella nostra classe User, diciamo che si tratta di una scelta che guarda alla semplicità, costruire una query al volo con i soli dati modificati è possibile ma è complesso, perché per essere certi di quel che facciamo dovremmo fare le seguenti cose:
- Leggere il record dal database
- Comparare tutte le colonne verificando quali sono modificate.
- Scrivere un metodo che componga la query con i soli dati e parametri necessari.
- Eseguire la query.
Se lavorassimo con un record con centinaia di campi, potrebbe valer la pena di farlo, ma altrimenti a mio avviso è solo uno spreco di tempo, SQL Server è abbastanza intelligente da gestire automaticamente le modifiche ai record.
Ci sarebbe anche un modo diverso di procedere, anzi, in realtà sarebbero due:
- Dovremo ricevere dal chiamante non solo la lista degli oggetti modificati, ma una seconda lista con gli oggetti che originalmente sono stati letti dal database.
- Comparare gli oggetti con lo stesso ID
- Scrivere un metodo che componga la query con i soli dati e parametri necessari.
- Eseguire la query.
Questo è uno dei modi per procedere è probabilmente più veloce perché una query su database è sempre più lenta, ma in compenso, dovendo tenere in memoria due versioni dello stesso oggetto (originale e nuova) utilizzeremo più risorse sul computer. Dipende sempre da quali sono le nostre esigenze.
Il terzo metodo, è quello da usare in caso ci siano problemi di concorrenza.
In questo caso, dovremmo applicare entrambe le tecniche qui sopra, perché quando ci sono problemi di concorrenza solitamente più utenti modificano lo stesso record contemporaneamente, pertanto per rendere le modifiche transazionali e più veloci possibile e soprattutto per controllare se qualcuno ha già modificato un record che stiamo per modificare dovremo fare le seguenti manovre:
- Ricevere la lista oggetti origine e la lista oggetti modificati
- Leggere l’oggetto da modificare
- Verificare se è stato modificato rispetto al nostro oggetto origine
- Verificare se le modifiche effettuate sono su campi diversi da quelli che abbiamo modificato noi
- In caso affermativo, potremo modificare quanto a noi necessario ed effettuare un Merge fra le modifiche trovate e le nostre e restituirlo alla User Interface.
- Nel caso vi fossero modifiche fatte da altri sui campi da noi modificati, dovremmo avere impostato nel codice o ricevere dal chiamante le regole di business che indicano come procedere, ve ne potrebbero essere diverse
- Sovrascrivere, regola base che dice che l’ultimo vince.
- Non modificare e restituire una lista dei record con conflitti e una lista dei valori trovati nel database perché sia l’utente a decidere cosa fare. (questo significa che la nostra user interface avrà un interfaccia di risoluzione conflitti che dovremo sviluppare specificamente per ogni tabella che ha questo problema).
- Non modificare i dati e restituire i nuovi record annullando le modifiche da noi effettuate così che l’utente debba rifarle (non proprio simpatico per l’utente ma anche in questo caso dipende dal tipo di applicazione).
Questo tipo di comportamento deve essere studiato prima di sviluppare le classi dati ed ovviamente deve essere concordato con il cliente in base alle sue necessità.
Due casi in cui si possa verificare tutto questo visti nella mia lunga carriera sono stati:
- Gestione della raccolta di carichi in groupage per autotrasportatori.
- Gestione della biglietteria di un teatro, anche se in questo caso la gestione essendo in real time è un po’ più complessa e non va neppure gestita sul database.
In tutti gli altri database di produzione da me sviluppati non ho mai avuto bisogno di simili controlli, la sola cosa da fare è introdurre l’uso delle Transazioni sul Database in aggiornamento, in modo da non provocare inconsistenze sui dati. Ma stiamo divagando un po’ troppo.
Torniamo ai nostri metodi di CRUD.
public Result<List<int>> Delete(List<User> usersToDelete)
{
Result<List<int>> ret = Result.Get<List<int>>();
try
{
using (SqlConnection cn = new SqlConnection(mConnnectionString))
{
SqlCommand cmd = new SqlCommand();
cmd.CommandText = SQL_Delete;
cmd.CommandType = CommandType.Text;
cmd.Connection = cn;
cn.Open();
foreach (User usr in usersToDelete)
{
SqlParameter[] para = new SqlParameter[] {
new SqlParameter("@ID", usr.ID)
};
cmd.Parameters.Clear();
cmd.Parameters.AddRange(para);
cmd.ExecuteNonQuery();
ret.Data.Add(usr.ID);
}
cn.Close();
}
}
catch (Exception ex)
{
ret.SetError(ex);
}
return (ret);
}Il nostro terzo metodo, la cancellazione, funziona in modo simile ai precedenti, ma ha bisogno di un solo parametro, l’ID univoco della riga da cancellare, ritornare la collection degli ID delle righe cancellate è sempre buona cosa in modo che la User Interface possa provvedere se necessario al clean dei dati su cui lavora. Anche se, solitamente io preferisco un aggiornamento complessivo e rifaccio una Select di tutta la tabella (ovviamente con i filtri ad hoc per le tabelle complesse).
public Result<List<User>> SelectAll()
{
Result<List<User>> ret = Result.Get<List<User>>();
try
{
using (SqlConnection cn = new SqlConnection(mConnnectionString))
{
SqlCommand cmd = new SqlCommand();
cmd.CommandText = SQL_Delete;
cmd.CommandType = CommandType.Text;
cmd.Connection = cn;
cn.Open();
SqlDataReader reader = cmd.ExecuteReader();
if (reader.HasRows)
{
while (reader.Read())
{
User usr = new User();
usr.ID = reader[User.FLD_ID].XxCheckDbNull<int>();
usr.Computer = reader[User.FLD_Computer].XxCheckDbNull<string>();
usr.LoginType = reader[User.FLD_LoginType].XxCheckDbNull<TypeOfLogin>(TypeOfLogin.None);
usr.Password = reader[User.FLD_Password].XxCheckDbNull<string>();
usr.UserName = reader[User.FLD_UserName].XxCheckDbNull<string>();
usr.WinDomain = reader[User.FLD_WinDomain].XxCheckDbNull<string>();
usr.WinUser = reader[User.FLD_WinUser].XxCheckDbNull<string>();
ret.Data.Add(usr);
}
}
}
}
catch (Exception ex)
{
ret.SetError(ex);
}
return (ret);
}Ultimo, ma non per questo meno importante, il metodo di lettura di tutta la tabella, in cui abbiamo usato una SqlConnection, un SqlCommand nessun parametro, ed un SqlDataReader, che è semplicemente un cursore read only forward only che ci permette di leggere i dati dal database una riga per volta senza quindi dover istanziare una DataTable con il contenuto della tabella SQL per poi buttarla, è il metodo più efficiente di istanziare le classi User con il contenuto del Database e come vedete abbiamo usato il nostro metodo extension XxCheckDbNull in entrambe le versioni per convertire gli object forniti dal generico SqlDataReader nei tipi di dato corretto.
In questo caso ho implementato un semplice SelectAll perché la mia tabella TbUsers conterrà al massimo qualche centinaio di righe, se sono fortunata e la userò in una grande azienda, pertanto non è necessario creare metodi con filtri sulla selezione. Se invece stessi lavorando su una tabella con migliaia o decine di migliaia di record probabilmente avrei bisogno di due diversi approcci:
- Avere un oggetto base con solo le property più utili alla ricerca dei dati da usare per una lista completa o filtrata tramite parametri.
- L’oggetto contenente i dati completi probabilmente sarebbe caricato con una chiamata con filtro su singolo record.
Questo tipo di approccio è utile sia per le tabelle singole con molte colonne e con migliaia di righe, ma anche con gli oggetti formati da più tabelle, come ad esempio possono essere le classi per la gestione di documenti di movimentazione magazzino, formati da Testata e Corpo, o in altri casi ove vi siano oggetti complessi.
Anche in questo caso però, se volete gestirli con semplicità, i Data Provider saranno simili a questo (salvo per le chiamate con dati parziali o con filtri specifici) e la composizione degli oggetti complessi sarà effettuata dalla classe Business che parlerà al database usando i Data Provider, mentre i Data Provider rimarranno per quanto possibile semplici e disegnati per gestire una singola tabella.
Riepilogo
Considerato che l’articolo è corposo, il codice per testare la classe Data Provider lo scriveremo nel prossimo articolo, anche perché ci farà da guida per lo sviluppo del Tier successivo, quello che ho chiamato Services classes. Pertanto riepiloghiamo di cosa abbiamo discusso:
- Come creare un progetto Class Library in una soluzione esistente.
- Come configurare il nome della .dll risultante e il namespace per i suoi oggetti.
- Come creare una classe Data Provider per una tabella in un database SQL Server.
- Come creare una classe Generic, la classe Result che ci permetterà di fornire dati ma anche eventuali errori a chi userà la classe Data Provider.
- Come usare il polimorfismo per creare due metodi con lo stesso nome ma diversi parametri.
- Cosa sono i metodi extension.
- Come creare quattro metodi extension per gestire la ricezione del valore DbNull dal database e la scrittura di un DbNull sul database.
- Come usare la classe Result ed i metodi extension nei quattro metodi di CRUD della nostra tabella TbUsers.
Potete scaricare il progetto di esempio dal link qui indicato:
Companion code, Lavorare con i dati – UsersDb Il Data Tier
Per qualsiasi domanda, commento, curiosità, approfondimento o per segnalare un errore usate link alla form di contatto in cima alla pagina.